
Recently, I decided to revisit a small homework assignment from grad school. We were tasked with experimenting with simple generative adversarial networks (or GANs). Although the state of the art has moved away from GANs as a method of image generation, I felt it might be interesting to try it out!
What is a Neural Net?
A traditional neural net takes some input, passes it through a few layers of neural nets, and then produces an output.
Source: Wikimedia
{kind=link}
By breaking down an image into individual pixels as inputs, you can fairly easily create simple classifiers. For example, you can easily tell when the image is “Not Hotdog”.
However, what if you want to do something more complex? What if you want to generate images? Today, we will take advantage of the most human of inventions: conflict.
Fighting to make a picture
Instead of one neural net, GANs ask why not use two? One neural net is tasked with generating the images, while the other is set up to discriminate the real examples of images from the fakes. The generator will be given random static as a seed for creating the images. This is why it’s called a generative adversarial network. The two networks are adversaries of each other! In this way, we can hopefully generate realistic images.
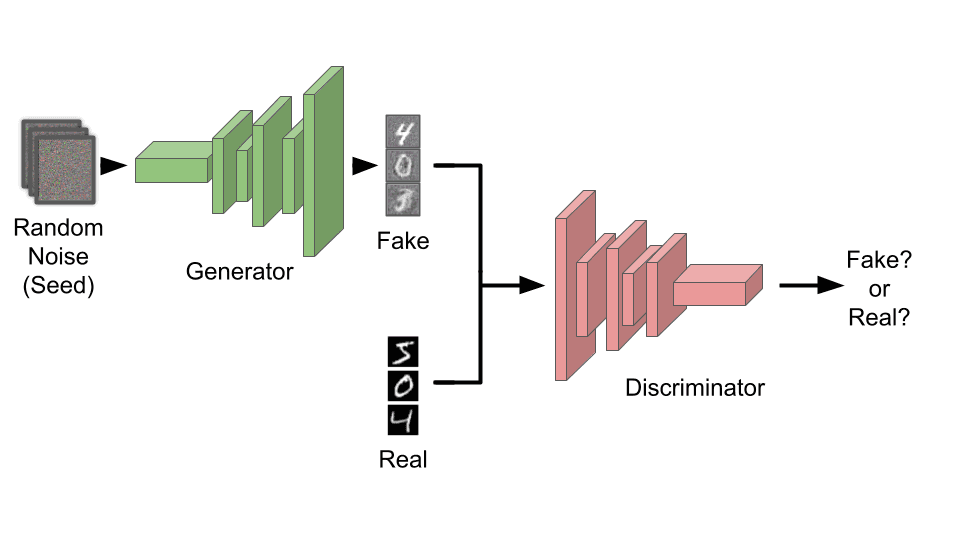
When the models are first created, they will both fail to function. The generator will create random static, while the discriminator will basically flip a coin when deciding if an image is real or not. However, utilizing gradient descent, both models will begin to make progress.
The discriminator will quickly differentiate the random static from the real training data. Next, the generator will determine how to trick the discriminator. Again, the discriminator tries to determine the difference between the real images and the generated fake ones. Back and forth, an arms race of machine learning drives both models to improve. With sufficiently strong models and time, the generator will get good enough to trick even people.
Giving hints
Although this basic concept does work, it doesn’t give us much control. Many of the datasets will contain multiple types (known as classes) of images (i.e. a car, the number 4, a woman’s shoe). We could create GANs for each class, however this can be time consuming and repetitive. Luckily, we can use something called conditional generative adversarial network (cGAN).
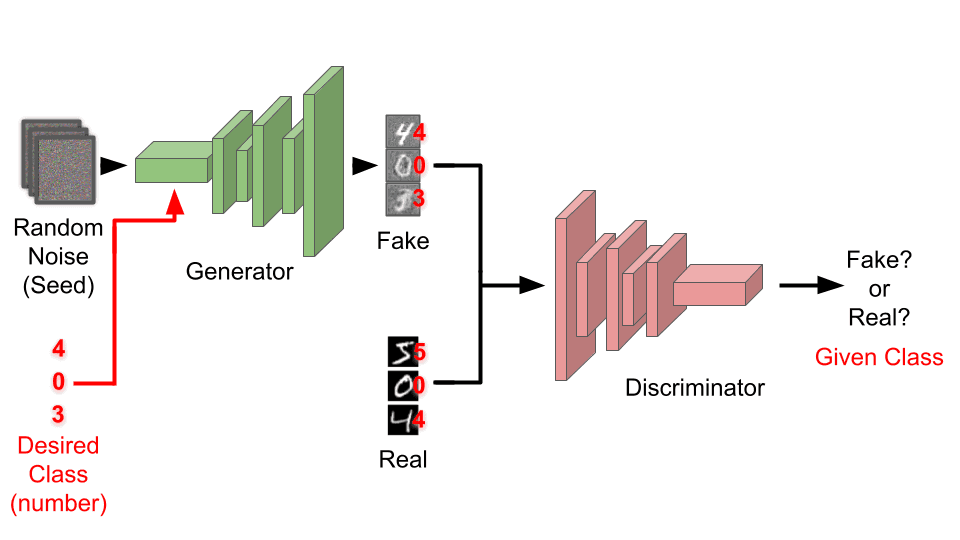
Above, we can see how the cGAN differs from the GAN (in red). The basic idea is in addition to the images themselves, we also provide the class as well. This gives both the generator and discriminator more context for what they are trying to do (generation and discrimination respectively). This approach is exactly what I was able to implement! To make things even more fun, I decided to run all of these models on my homelab’s GPU.
Examples
The rest of this blog post will show case some of the success, and failures, I encountered. You may need to wait for the animations to restart before you can watch the full training process from beginning to end.
MNIST
Whenever you attempt something, always start with the simplest case. For this project, I began with the MNIST dataset. This datasets contains thousands of examples of hand written numbers.

Above, we can see the training process. Each frame of the animation is an epoch (a step) of training. For each class (the numbers 0 to 9), we can see how the generated numbers appear almost random. As the discriminator gets better, the generator must improve as well. Over time, the fuzzy images become crisp and clear. After several dozen rounds of training, the generator produces fairly recognizable numbers.
Remember, the generator is not simply copying existing examples of numbers. It is instead creating new numbers that are indistinguishable from the examples.
That being said, it could be that the generator has memorized examples for each number. Below, we can see three examples of each class (i.e. the numbers 0-9).

Although each number is recognizable, the variance between each example of the same class is minimal. It’s clear that the GAN may have just memorized a single example and learned to slightly vary it. This is often known as Mode Collapse. Because our generator is trying to deceive the discriminator, optimizing a single output can be a fairly easy strategy. This is one of the main drawbacks to GAN.
FashionMNIST
While generating numbers is perhaps academically interesting, it still feels kinda abstract. Instead, let’s try generating something every fan of Legally Blonde and The Devil Wears Prada will appreciate: Fashion!

The FashionMNIST dataset contains black and white images of pants, shirts, shoes, etc. While it’s far from generating realistic images of cartoon characters like ChatGPT, we can see some promise.

Above, we can see how the generated images become clearer and distinct. Unlike the numbers, we can see that the GAN creates much more varied and unique items.

Although the generated images are not as clear in the FashionMNIST example as with the numbers, the variance between images of the same class is much better. The silhouettes of shoes and bags especially distinct from each other. Perhaps a larger model or longer training time would produce better output.
CIFAR10
Lastly, I tried the CIFAR10 dataset. Below, we can see what some of these images look like.

Examples from cifar10 dataset
Unlike the previous two datasets, these images contain color and much more complicated structures. Along with deer and dogs, we also have images of trucks and airplanes. Because of this added complexity, the cGAN approach did not work at all. Instead I utilized a Deep Convolutional GAN (dcgan).
Without going into too much detail, DCGANs replace fully connected layers with convolutional layers, which better capture the spatial structure of images and allow deeper models to improve performance. This should allow our model to generate more complicated shapes and structures.

To cut to the chase, this still didn’t work well. Again, we see above how the learning process progressed. While you may notice early improvements, the model has clearly hit a wall. Perhaps further tuning or model improvements could fix the issue. However, I decided this was a good stopping point.
Conclusion
Transformers, with their attention mechanisms, have largely surpassed GANs for many generative tasks, particularly in text-to-image models like DALL·E and video models like OpenAI’s Sora. Often, AI has been abstracted away from the consumer. While we might expect that we can throw an AI model on a set of data and expect an instant solution, that is not always the case. Although GANs have lost interest with the rise of the much more powerful transformer (the T in ChatGPT), it is still interesting to understand their mechanics and functionality.
In the future, I hope to explore much more powerful and useful models. Perhaps, I’ll even create a model that does something much more useful.