Today, I’d like to talk about prettyprint.dev, the developer focused formatter I rebuilt this week.
👉 Try it now or read about it below.
Introduction
Many years ago, I had an annoying and narrow problem. I kept having to format random json blobs:
{'user':{'id':123456,'name':'Alice Doe','email':'alice@example.com','isActive':true,'lastLogin':null,'preferences':{'theme':'dark','notifications':{'email':true,'sms':false,'push':true},'dashboardLayout':['chart','summary','activity']}},'metrics':{'visits':10523,'conversionRate':0.045,'bounceRate':0.63,'avgSessionDuration':312.5,'regions':[{'name':'NorthAmerica','users':5200},{'name':'Europe','users':3123},{'name':'Asia','users':2100}]},'features':[{'name':'Chat','enabled':true,'beta':false,'releaseDate':'2023-11-01T12:00:00Z'},{'name':'Analytics','enabled':true,'beta':true,'releaseDate':null}],'notes':['Welcometothesystem!','Youraccountiscurrentlyintrialmode.','Upgradetoaccessallfeatures.'],'emptyFields':{'optionalString':null,'optionalArray':[],'optionalObject':{}},'serverStatus':{'uptimeSeconds':986320,'loadAverage':[0.23,0.31,0.29],'diskUsage':{'totalGB':500,'usedGB':213.7,'freeGB':286.3,'mounts':[{'name':'/','usedPercent':42.3},{'name':'/home','usedPercent':51.0}]}}}JSON is a common machine/human readable format that APIs, logs, etc will utilize. If you work extensively with software, you’ve likely had to deal with JSON. Although it’s technically human readable, when it’s compact like above, it’s fairly impossible to follow. There are some bash commands, but I often find it cumbersome to use:
echo "{'user':{'id':123456,'name':'Alice Doe','email':'alice@example.com','isActive':true,'lastLogin':null,'preferences':{'theme':'dark','notifications':{'email':true,'sms':false,'push':true},'dashboardLayout':['chart','summary','activity']}},'metrics':{'visits':10523,'conversionRate':0.045,'bounceRate':0.63,'avgSessionDuration':312.5,'regions':[{'name':'NorthAmerica','users':5200},{'name':'Europe','users':3123},{'name':'Asia','users':2100}]},'features':[{'name':'Chat','enabled':true,'beta':false,'releaseDate':'2023-11-01T12:00:00Z'},{'name':'Analytics','enabled':true,'beta':true,'releaseDate':null}],'notes':['Welcometothesystem!','Youraccountiscurrentlyintrialmode.','Upgradetoaccessallfeatures.'],'emptyFields':{'optionalString':null,'optionalArray':[],'optionalObject':{}},'serverStatus':{'uptimeSeconds':986320,'loadAverage':[0.23,0.31,0.29],'diskUsage':{'totalGB':500,'usedGB':213.7,'freeGB':286.3,'mounts':[{'name':'/','usedPercent':42.3},{'name':'/home','usedPercent':51.0}]}}}" | python -m json.toolThe above command doesn’t even work!
bash: !','Youraccountiscurrentlyintrialmode.','Upgradetoaccessallfeatures.'],'emptyFields': event not foundThe exclamation point (!) seems to break our command. Fixing this issue can be time-consumingly annoying.
Luckily, there are free websites that will format your JSON for you! Unfortunately, they often fail when your JSON doesn’t exactly follow the standard. For example, the above blob uses the wrong quote:
Parse error on line 1:
{'user':{'id':123456,
-^
Expecting 'STRING', '}', got 'undefined'In college, I kept having to find and replace the quotes in my JSON blobs. I found this very cumbersome. That’s when I decided to build prettyprint.dev
Version 1
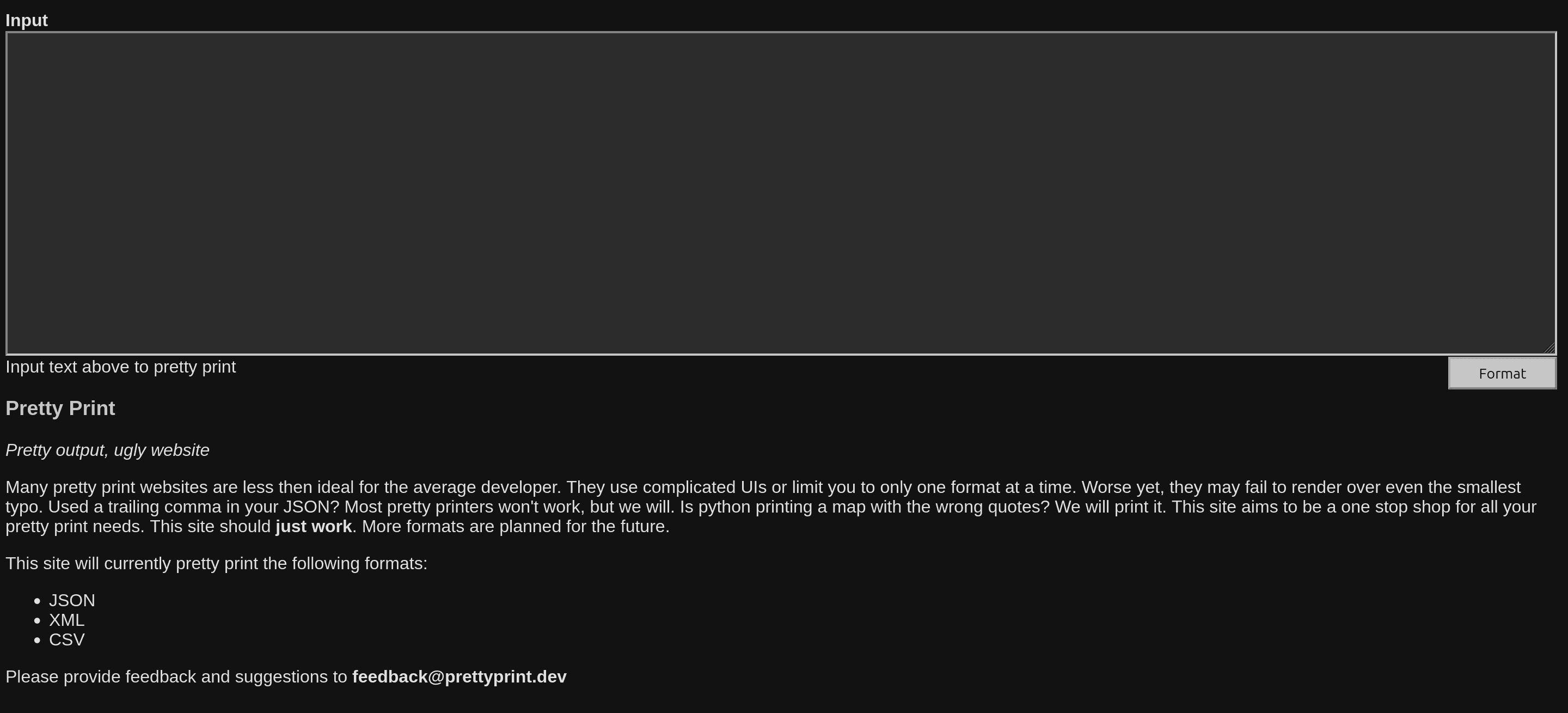
Above, you can see what I made a few years ago. The implementation is basic and fairly limited. I used hard-coded HTML and JavaScript. My JSON parsing logic was fairly simple:
- Find and replace all
'with"(except those within"") - Remove trailing commas (i.e.
[1,2,3,]) - HTML encode special characters (
<>&) - Add basic syntax highlighting

Issues with v1
This solved most of the usual issues I ran into with JSON. However, it was still quite flaky. It turns out, there are many more edge cases and issues that my basic implementation fails to solve. Even worse, I decided to expand the formats supported by the website. At the time, the methodology for determining the input’s format was imprecise and uncontrollable. If the code decides your JSON blob is actually a CSV, it was impossible to fix.
Even years later, the issues remained. Finally, I decided to take this week to fix it.
Version 2 (today)
I decided to rewrite the entire site using Next.JS. I also completely overhauled the way the code detects, parses and formats the provided input. Because of how modular it is, I can now support several times more formats and even allow drag and drop input.
The basic architecture is as follows:
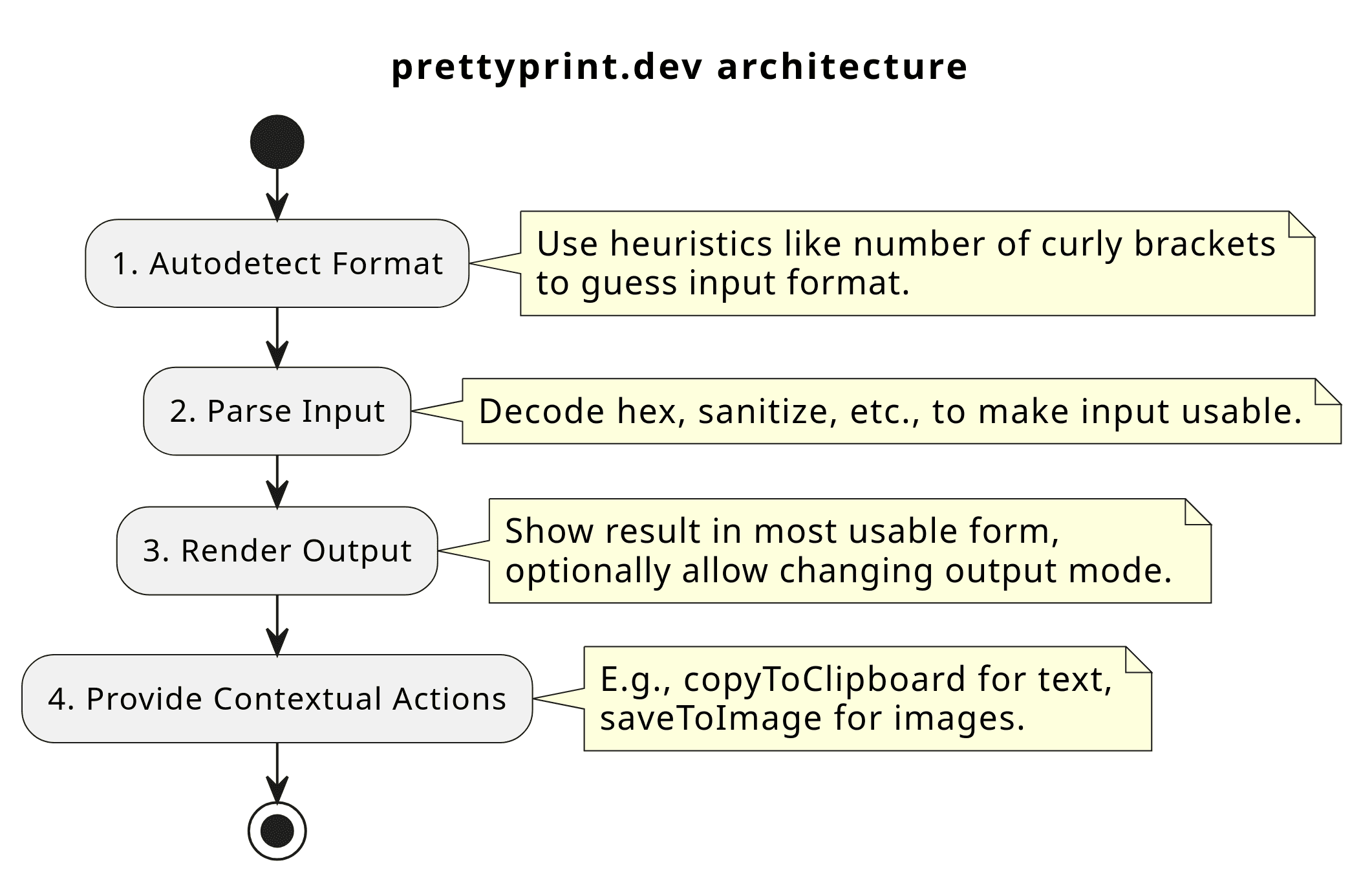
The general pipeline is autodetect -> parse -> render.
Autodetect
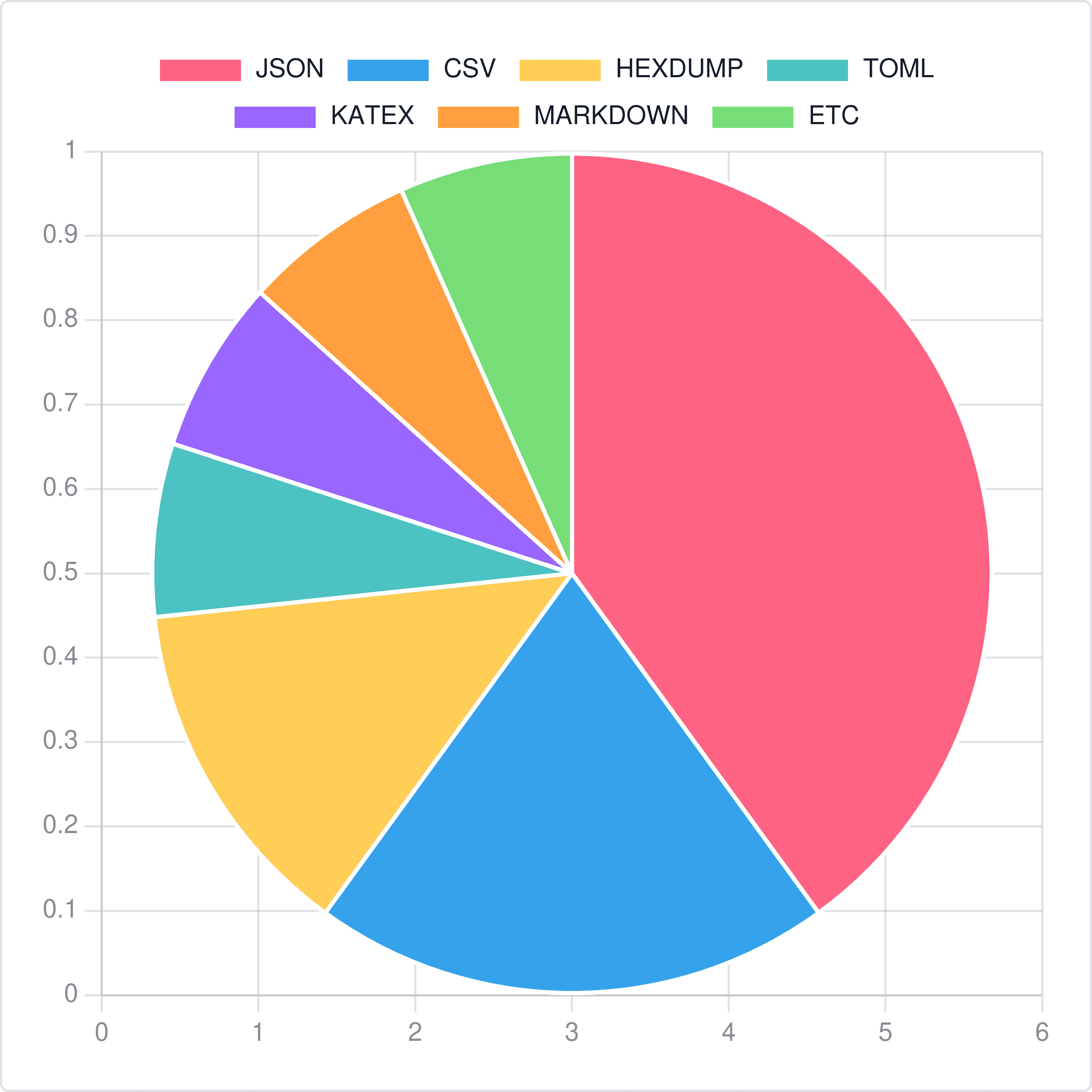
First, we need to determine the input’s format. At the moment, prettyprint.dev supports the following at the time of writing:
- JSON
- CSV
- TSV
- TOML
- KATEX
- Markdown
- Hexdumps
- Binarydumps
- Color codes (i.e. #FFAADA)
- Base64 URI Encoded images
- PlantUML (still a bit WIP)
That’s a lot of formats! But how do we determine which the user wants to use? For example, is this a CSV or a JSON?
[["1","2","3"],
["1","2","3"]]If we believe it is json, it will look like:
[
[
"1",
"2",
"3"
],
[
"1",
"2",
"3"
]
]However, as a CSV, it looks like:
| [[“1” | “2” | “3”] | |
|---|---|---|---|
| [“1” | “2” | “3”]] |
Because both are “valid”, we can’t simply run the input through all our formats and reject those that throw errors. Instead, prettyprint.dev is based on a heuristic system.
Heuristics
We start by counting all the important characters in the string (i.e. {}=\/, etc). I also count certain keywords (i.e. \mathtt, \sqrt, etc). For each character, we assign a multiplier:
| element | JSON | CSV | Katex |
|---|---|---|---|
| { | x10 | x-10 | x0 |
| } | x10 | x-10 | x0 |
| : | x3 | x-3 | x0 |
| ” | x4 | x2 | x0 |
| \sqrt | x0 | x0 | x4 |
| \mathtt | x0 | x0 | x10 |
We then count the number of occurrences for each element, multiply that number by its respective multiplier, and sum it all together:
In practice, I also include other rules (i.e. JSON strings will never start with @). Whichever format has the best score, is the format we’ll use. I also let users specify the desired format using a dropdown.

Parse
This step is the simplest. For whatever format we’re using, we will start by converting the raw string into something useable.
For example, for JSON we’ll utilize JSON5.parse. For, CSV we have papaparse. Etc, etc.
In the future I may decide to implement my own JSON parser, however JSON5 is much more forgiving than the built in JSON Parser.
This intermediate steps allows us to prepare for which ever format we decide to render the output.
Render
Finally, we need to render our output to the screen. In v1, I would only render the output one way per format. For each format, I have decided on a default output type. For CSV, prettyprint.dev defaults to a graph:
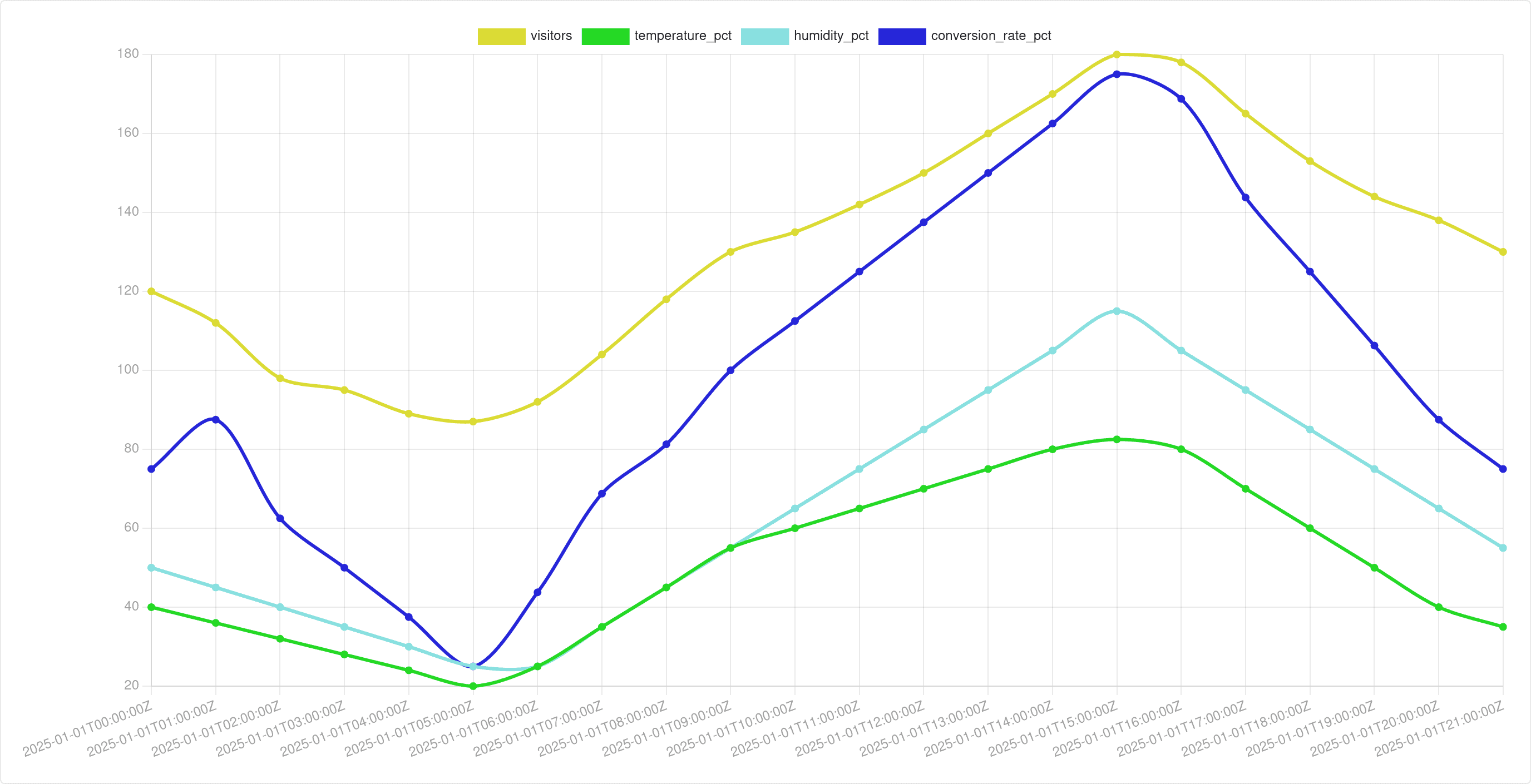
In v2, I decided that we should support multiple options. For example, CSV formats supports graphs, html table, and markdown table:
Not all formats will have multiple output types, but I made sure to implement them where it makes sense.
Other features
Finally, there are a myriad of quality of life features I’ve added to prettyprint.dev.
- You can drag and drop files into the input
- Some outputs will include action buttons that make interactions easier
- Custom themes (light, dark, green, etc) that persist between sessions
- A demo mode to help “sell” the site and all its features
And so much more!
Conclusion

Finally, after years of indecision and laziness, I put in the week of work and cobbled together a proper version of prettyprint.dev. I have big plans for future format support (YAML, protobuf, etc). If you use prettyprint.dev, I’d love to hear how it fits into your workflow.
If you have ideas, or feedback, please send it to contact@curtislowder.com.
I’m especially interested in edge cases and weird inputs. If you can break the auto-detector, I’d love to know!